Redis 是一个用 C 实现的开源、支持网络、基于内存、分布式、可选持久性的键值对存储数据库。
线程模型
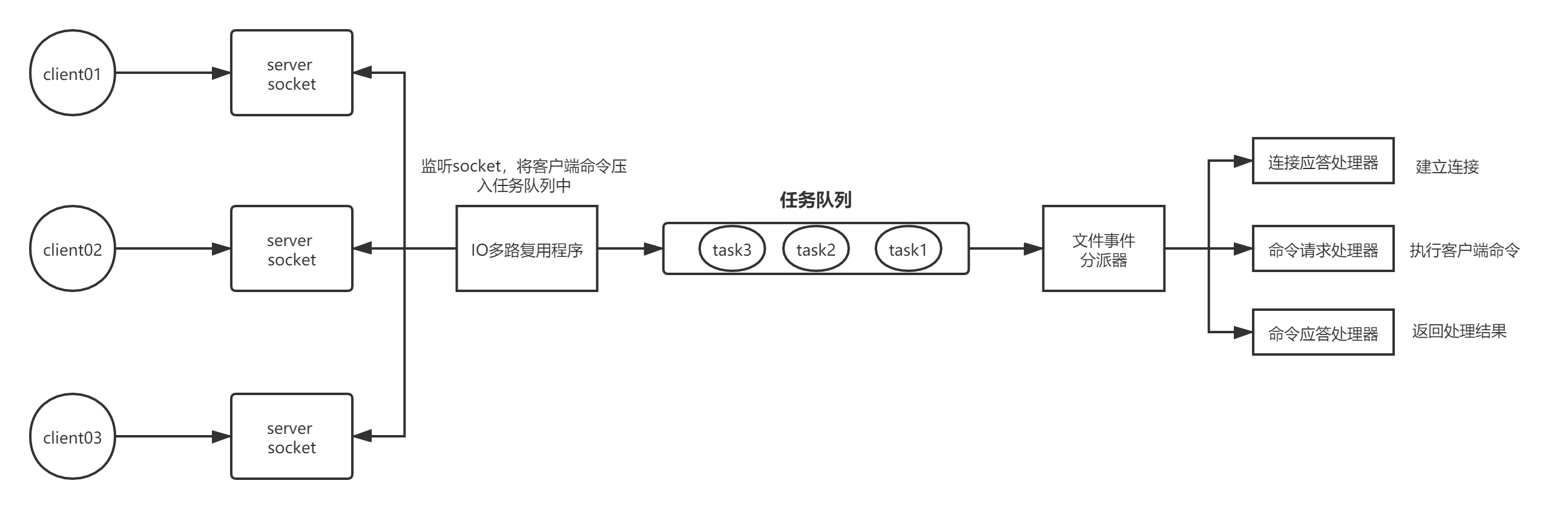
Redis 内部使用文件事件处理器 file event handler,它是单线程的,所以 Redis 是单线程模型。它采用IO多路复用机制同时监听多个 socket,将产生事件的 socket 压入内存队列中,事件分派器根据 socket 上的事件类型来选择对应的事件处理器进行处理。
数据结构
简单动态字符串 Simple Dynamic String
Redis 没有使用 C 中传统的字符串表示,而是自己创建了这样一个类型作为自己的默认字符串格式。Redis 只会在无需更改字符串内容的地方使用 C 的字符串。
SDS 是由头部 sdshdr(struct)和存储区 buf(char [])两部分组成。在 sdshdr 中记录了未使用长度 free(int),总长度 len (int),以及存储区的指针 buf。而存储区保存了 C 的惯例,以 ‘\0’ 作为字符串的结尾。
SDS因为存储了 free 和 len,并且使用字节数组存储内容,所以可以以 O(1) 获取字符串的长度,而不像 C 那样需要遍历它。并且因为存储了总长 len,所以写入更新时不会超出分配的空间而造成缓冲区溢出。写入时 Redis 会快速检查 free 和 len,当剩余空间不足时会扩容一倍再进行修改(最大扩容1MB);而删除更新时(注意不是删除整个值),因为记录了 free,不会在每次删除更新时重分配内存,而实现了懒释放。这种机制对于需要面对频繁更改的业务场景的 redis 来说能节省不少性能开销。
当然 Redis 也提供了相应的 API 让我们在需要时真正释放 free 空间,而不用担心造成内存的浪费。
字典
简介
Redis 的字典依然分为两部分,由一个头部 dict 和一个 Hashtable 组成。不同的是 Redis 为它的 Hashtable 也设计了一个头部 dictht ( Dict HashTable )。
dict 头部保存了类型函数指针 type 和私有数据,并且保存有 Rehash Index ( rehashidx ) 和指向两张哈希表表头的指针 (ht) 。当添加键值时,调用类型函数指针中的哈希函数计算出它应该放在哪个位置。dictht 保存有哈希表的数组头指针 table、数组大小 size、数组掩码 sizemask ( =size-1 ) 和已使用数量 used。当不在进行 rehash 的时候,dict->rehashidx 为-1,而第二张哈希表处于空闲状态,仅存在表头 ht[1],而其中的 table 指针为空。
Rehash
当哈希表 used/size >= 1 则表明该字典需要进行 rehash ( 特别地,如果在进行后台持久化时,该值会被设定为 5 ) 。Rehash 采用分治法将全部的计算量分摊到每一次对其的增删查改上。首先将 rehashidx 设为 0 代表每次操作需要附加 rehash 操作。而每次的增删查改会顺带将第一张表 ht[0][rehashidx] 上的内容 Rehash 到第二张表 ht[1][dict->type->hashFunction(key) & dict->ht[1]->sizemask] 上,并将 rehashidx+1。
当 rehash 完成后,第一张表的空间将被释放,而第二张表头的 table 指针会被赋值给第一张表。
分布式
主从:SLAVEOF <master_ip> <master_port>
当从服务器(以下简称从)接收到 slaveof 命令后,首先保存这两个值,并返回OK,在这之后,从才会开始复制工作。也可以在从的 redis.conf 中设置这条命令。
首先从会根据相关属性建立与主服务器(以下简称主)的连接,如果建立成功则创建一个处理器用于处理复制工作。整个工作是通过“从向主发送命令”来进行。当从成为主的客户端后,首先发送一个 Ping 命令检查 Socket 连接是否正常,以及主能否正常处理命令。如果 ping 出现异常则会断开并重新建立连接。
此后根据配置文件中的 masterauth 决定是否发送 AUTH <password> 命令。当主的 requirepass 和从的 masterauth 字段相同或都不存在时才会通过身份验证,否则都会返回错误使中止复制。
身份验证之后,从向主发送自己的监听端口,方便主在有数据更改时通知从。在此之后,主也成为了从的客户端,然后就会开始同步。同步分为全量和增量。其中全量复制是通过从发送 SYNC 命令,然后主发送 RDB 文件 和缓冲区的写命令完成的,而从执行 RDB 载入的时候是阻塞的,无法响应外界命令。
而如果仅是网络中断导致的重新复制,则会启动增量更新。在同步过程中主从各自维护一个复制偏移量 offset,增量更新时会从较少的 offset 开始传递数据。传递数据前,从将自己维护的 offset 发送给主,如果 offset 超出了主的缓冲区,或者传递数据时主的 runid 与从所保存的不一致,就会启动全量更新。
而其余部分与其他主从系统相似,包括心跳机制、最小从数、最小时延。
当主服务器宕机后,需要人工更换主服务器,所以缺乏高可用性。Redis 提供了主从复制的高可用解决方案 哨兵 Sentinel。它们之间互相连接并共同监视所有服务器的健康状态。
集群: CLUSTER MEET <ip> <port>
集群是 Redis 提供的分布式数据库解决方案,通过分片 ( Sharding ) 来进行数据共享,并提供复制和故障转移功能。每当集群内有节点进行 Meet 握手或是主从复制、故障转移时都会通过 Gossip 协议通告全集群。
一个集群被分片为若干个槽,需要所有槽都有节点负责才能使集群上线。每个节点会维护一个状态列表,存放公共信息 ( 比如槽的归属 ) 。每当有命令通过一个节点进入集群时,该节点负责计算这个命令归属于哪一个槽,如果属于自己负责的那就立刻处理,否则返回重定向至对应节点处理。
当一个主下线时,对应的槽由其从服务器之一接管,并成为主。下线的服务器恢复之后,会成为它的从。
Gossip 协议可能是最有趣的一致性协议。它基于六度分隔理论生动形象地说明了八(bìng)卦(dú)传(gǎn)播(rǎn)的迅速。
高可用
1. RDB 持久化
RDB 持久化可以手动执行,也可以根据配置定期执行。有两个命令可以用于生成 RDB 文件,分别是 SAVE 和 BGSAVE 。 SAVE 会阻塞 Redis 进程直至 RDB 文件创建完毕,而 BGSAVE 会 fork 出一个子进程负责创建 RDB。
为了避免父进程与子进程同时执行 rdbSave 调用而产生竞争,SAVE 和 BGSAVE 是禁止同时执行的。
2. AOF 持久化 (Append Only File)
AOF 持久化是通过保存 Redis 所执行的写命令来记录数据库状态的,分为命令追加 ( append )、文件写入、文件同步 ( sync ) 三个步骤。当 AOF 处于开启状态时,服务器执行完一个命令后,会以协议格式(文本)写入 aof_buf 缓冲区,并在一次事件循环后根据配置选择是否要求操作系统立刻与磁盘上的 AOF 文件同步。该同步会开启一个新线程负责执行。
3. 哨兵 Sentinel: $ redis-sentinel /path/to/your/sentinel.conf
哨兵是分布式 Redis 故障转移机制中用于监视其他 Redis 的 Redis。Redis 的哨兵可以有多个,并且互相连接。
当一个哨兵被启动时:
- 初始化一个正常的 Redis 并将这个 Redis 的代码替换为哨兵专用代码。
- 初始化哨兵并创建与所有服务器的命令连接和订阅连接,获取其信息。
哨兵通过心跳检测某个服务器是否主观下线。如果主被检测为主观下线,就会询问其他哨兵,其他哨兵会回复他视角下的主的状态,主的id和当前纪元。达到足够数量后,哨兵们内部选举出一个哨兵主持下一纪元的主服务器选举。